Java爬虫入门(一)
环境:JDK 10.0.2
IDE:Eclipse
简介
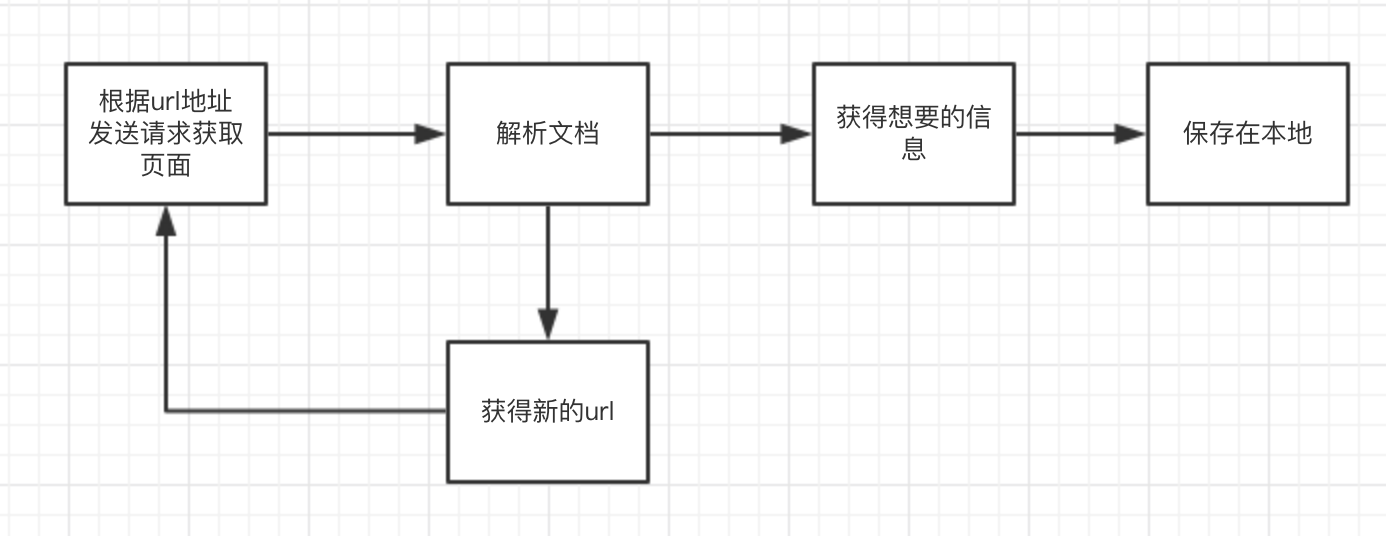
前几天尝试了一下用java爬虫爬取学校网站的照片,觉得挺有趣,在这里分享给大家,并从一个简单的爬虫程序逐渐变成一个复杂的爬虫程序,首先给出初步的结构设计:
准备
Jsoup
Jsoup 是一款Java 的HTML解析器,可直接解析某个URL地址、HTML文本内容。它提供了一套非常省力的API,可通过DOM,CSS以及类似于jQuery的操作方法来取出和操作数据。对于初学爬虫只需要了解一下基本使用方法就可以了,下面简单地举几个例子来介绍一下。
Jsoup.parse()方法是我们会经常用到的方法,它可以从字符串、文件、URL等参数加载html,返回一个Document类型的对象,例如从字符串加载html:
String html = "<html><head><title>test</title></head>"
+ "<body>body content</body></html>";
Document document = Jsoup.parse(html);
第二个重要的方法是Document类中的select()方法,在获得了document对象之后,就可以通过这个方法获得元素,例如获得所有a标签:
Elements links = document.select("a");
如果要筛选出属性中含有href的a元素,可以这样
Elements links = document.select("a[href]");
其他元素也是类似这样,那么获得了Elements对象之后怎么获得链接的内容呢?这也很简单:
String href = links.attr("href");
这样就可以获得href中的内容,但是有些网页里面的href给出的路径是相对路径,如果使用相对路径作为链接去爬网页往往会导致访问错误的网址,所以应该这样做
Document document = Jsoup.parse(html,your_url);
Elements links = document.select("a[href]");
String href = Element.attr("abs:href");
其中your_url是你设定的绝对路径,例如当your_url=http://https://github.com/hly1998/hly.github-io,获取的链接中href=”index”时,Element.attr(“abs:href”)返回的是“http://https://github.com/hly1998/hly.github-io/index”
使用Jsoup还可以获取例如的标签去获取图片,获取某个包含某种class,id的元素等,如果你想进一步了解可以参考Jsoup教程
Httpclient
如果你要向某个网址发送请求,可以用java原生的方法,也可以使用apache.commons.httpclient包中的方法,当然我更推荐后者,因为后者方法更加丰富。为了使用Httpclient类,你需要导入包commons-httpclient-3.1.jar,你可以在我的仓库里找到这个包。那么接下来我来简单介绍一下怎么去访问一个网页。 第一步先生成一个HttpClient对象,设置连接超时,我这里设置了5s:
HttpClient httpClient = new HttpClient();
httpClient.getHttpConnectionManager().getParams().setConnectionTimeout(5000);
第二步获得GetMethod对象,并设置请求超时、请求重试处理
GetMethod getMethod = new GetMethod(url);
getMethod.getParams().setParameter(HttpMethodParams.SO_TIMEOUT, 5000);
getMethod.getParams().setParameter(HttpMethodParams.RETRY_HANDLER, new DefaultHttpMethodRetryHandler());
第三步执行请求,然后以字节形式获取网页的内容:
byte[] responseBody = getMethod.getResponseBody();
最后不要忘记释放连接:
getMethod.releaseConnection();
UniversalDetector
我们在使用爬虫时往往需要知道一个网页的字符编码,有些网页会在开头说明网页编码,这时我们可以通过正则表达式来获取编码,但有些网页不会说明编码,这是就需要我们自己去试探该网页的编码,mozilla.universalchardet.UniversalDetector包可以帮助我们方便地处理这个问题。使用方法很简单,假设你获得了网页代码的字节串(用上面的方法我们已经获得了),那么你只需要如下简单的操作:
UniversalDetector detector = new UniversalDetector(null);
detector.handleData(bytes, 0, bytes.length);
detector.dataEnd();
String encoding = detector.getDetectedCharset();
detector.reset();
但是我们不能确保每次都能用这个方法能成功获得编码,为了保险起见,还可以在这个方法获取失败时使用正则表达式来获取。
有了这些准备,我们就可以开始编写爬虫啦!我将在下一节介绍一个最简单爬虫的编写。